|
|
|
|
|
Статистический анализ экспериментальных данных и способы наглядного представления результатов
Методы вторичной статистической обработки результатов экспериментаС помощью вторичных методов статистический обработки экспериментальных данных непосредственно проверяются, доказываются или опровергаются гипотезы, связанные с экспериментом. Эти методы, как правило, сложнее, чем методы первичной статистической обработки, и требуют от исследователя хорошей подготовки в области элементарной математики и статистики. Обсуждаемую группу методов можно разделить на несколько подгрупп: 1. Регрессионное исчисление. 2. Методы сравнения между собой двух или нескольких элементарных статистик (средних, дисперсий и т.п.), относящихся к разным выборкам. 3. Методы установления статистических взаимосвязей между переменными, например их корреляции друг с другом. 4. Методы выявления внутренней статистической структуры эмпирических данных (например, факторный анализ). Рассмотрим каждую из выделенных подгрупп методов вторичной статистической обработки на примерах. Регрессионное исчисление — это метод математической статистики, позволяющий свести частные, разрозненные данные к некоторому линейному графику, приблизительно отражающему их внутреннюю взаимосвязь, и получить возможность по значению одной из переменных приблизительно оценивать вероятное значение другой переменной.
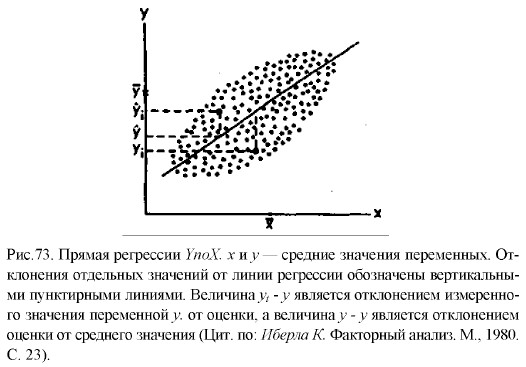
Воспользуемся для графического представления взаимосвязанных значений двух переменных х и у точками на графике (рис. 73). Поставим перед собой задачу: заменить точки на графике линией прямой регрессии, наилучшим образом представляющей взаимосвязь, существующую между данными переменными. Иными словами, задача заключается в том, чтобы через скопление точек, имеющихся на этом графике, провести прямую линию, пользуясь которой по значению одной из переменных, х или у, можно приблизительно судить о значении другой переменной. Для того чтобы решить эту задачу, необходимо правильно найти коэффициенты а и b в уравнении искомой прямой: у = ах + b. Это уравнение представляет прямую на графике и называется уравнением прямой регрессии. Формулы для подсчета коэффициентов а и b являются следующими:
где х., у1 — частные значения переменных X и Y, которым соответствуют точки на графике; х, у — средние значения тех же самых переменных; n — число первичных значений или точек на графике. Для сравнения выборочных средних величин, принадлежащих к двум совокупностям данных, и для решения вопроса о том, отличаются ли средние значения статистически достоверно друг от друга, нередко используют t-критерий Стъюдента. Его основная формула выглядит следующим образом:
где x1 — среднее значение переменной по одной выборке данных; х2 — среднее значение переменной по другой выборке данных; m1 и m2 — интегрированные показатели отклонений частных значений из двух сравниваемых выборок от соответствующих им средних величин. m1, и m2 в свою очередь вычисляются по следующим формулам:
где
n1, — число частных значений переменной в первой выборке; n2 — число частных значений переменной по второй выборке. После того как при помощи приведенной выше формулы вычислен показатель t, по таблице 32 для заданного числа степеней свободы, равного n1 + n2 - 2, и избранной вероятности допустимой ошибки1 находят нужное табличное значение t и сравнивают с ними вычисленное значение t. 1 Степени свободы и вероятность допустимой ошибки — специальные математико-статистические термины, содержание которых мы здесь не будем рассматривать. Если вычисленное значение t больше или равно табличному, то делают вывод о том, что сравниваемые средние значения из двух выборок действительно статистически достоверно различаются с вероятностью допустимой ошибки, меньшей или равной избранной. Рассмотрим процедуру вычисления t-критерия Стъюдента и определения на его основе разницы в средних величинах на конкретном примере. Допустим, что имеются следующие две выборки экспериментальных данных: 2, 4, 5, 3, 2, 1, 3, 2, 6, 4, и 4, 5, 6, 4, 4, 3, 5, 2, 2, 7. Средние значения по этим двум выборкам соответственно равны 3,2 и 4,2. Кажется, что они существенно друг от друга отличаются. Но так ли это и насколько статистически достоверны эти различия? На данный вопрос может точно ответить только статистический анализ с использованием описанного статистического критерия. Воспользуемся этим критерием. Определим сначала выборочные дисперсии для двух сравниваемых выборок значений:
Поставим найденные значения дисперсий в формулу для подсчета m a t к вычислим показатель t
Сравним его значение с табличным для числа степеней свободы 10 + 10 - 2 = 18. Зададим вероятность допустимой ошибки, равной 0,05, и убедимся в том, что для данного числа степеней свободы и заданной вероятности допустимой ошибки значение t должно быть не меньше чем 2,10. У нас же этот показатель оказался равным 1,47, т.е. меньше табличного. Следовательно, гипотеза о том, что выборочные средние, равные в нашем случае 3,2 и 4,2, статистически достоверно отличаются друг от друга, не подтвердилась, хотя на первый взгляд казалось, что такие различия существуют. Вероятность допустимой ошибки, равная и меньшая чем 0,05, считается достаточной для научно убедительных выводов. Чем меньше эта вероятность, тем точнее и убедительнее делаемые выводы. Например, избрав вероятность допустимой ошибки, равную 0,05, мы обеспечиваем точность расчетов 95% и допускаем ошибку, не превышающую 5%, а выбор вероятности допустимой ошибки 0,001 гарантирует точность расчетов, превышающую 99,99%, или ошибку, меньшую чем 0,01%. Описанная методика сравнения средних величин по критерию Стъюдента в практике применяется тогда, когда необходимо, например, установить, удался или не удался эксперимент, оказал или не оказал он влияние на уровень развития того психологического качества, для изменения которого предназначался. Допустим, что в некотором учебном заведении вводится новая экспериментальная программа или методика обучения, рассчитанная на то, чтобы улучшить знания учащихся, повысить уровень их интеллектуального развития. В этом случае выясняется причинно-следственная связь между независимой переменной — программой или методикой и зависимой переменной — знаниями или уровнем интеллектуального развития. Соответствующая гипотеза гласит: «Введение новой учебной программы или методики обучения должно будет существенно улучшить знания или повысить уровень интеллектуального развития учащихся». Предположим, что данный эксперимент проводится по схеме, предполагающей оценки зависимой переменной в начале и в конце эксперимента. Получив такие оценки и вычислив средние по всей изученной выборке испытуемых, мы можем воспользоваться критерием Стъюдента для точного установления наличия или отсутствия статистически достоверных различий между средними до и после эксперимента. Если окажется, что они действительно достоверно различаются, то можно будет сделать определенный вывод о том, что эксперимент удался. В противном случае нет убедительных оснований для такого вывода даже в том случае, если сами средние величины в начале и в конце эксперимента по своим абсолютным значениям различны. Иногда в процессе проведения эксперимента возникает специальная задача сравнения не абсолютных средних значений некоторых величин до и после эксперимента, а частотных, например процентных, распределений данных. Допустим, что для экспериментального исследования была взята выборка из 100 учащихся и с ними проведен формирующий эксперимент. Предположим также, что до эксперимента 30 человек успевали на «удовлетворительно», 30 — на «хорошо», а остальные 40 — на «отлично». После эксперимента ситуация изменилась. Теперь на «удовлетворительно» успевают только 10 учащихся, на «хорошо» — 45 учащихся и на «отлично» — остальные 45 учащихся. Можно ли, опираясь на эти данные, утверждать, что формирующий эксперимент, направленный на улучшение успеваемости, удался? Для ответа на данный вопрос можно воспользоваться статистикой, называемой х2-критерий («хи-квадрат критерий»). Его формула выглядит следующим образом:
где Рк — частоты результатов наблюдений до эксперимента; Vk — частоты результатов наблюдений, сделанных после эксперимента; m — общее число групп, на которые разделились результаты наблюдений. Воспользуемся приведенным выше примером для того, чтобы показать, как работает хи-квадрат критерий. В данном примере переменная Рк принимает следующие значения: 30%, 30%, 40%, а переменная Vk—такие значения: 10%, 45%, 45%.
|



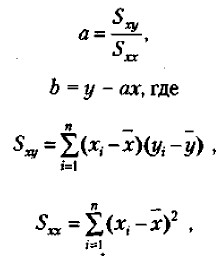
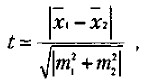

 — выборочная дисперсия первой переменной (по первой выборке);
— выборочная дисперсия первой переменной (по первой выборке);
 — выборочная дисперсия второй переменной (по второй выборке);
— выборочная дисперсия второй переменной (по второй выборке);
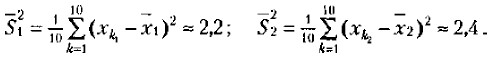
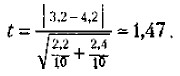
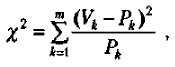
|
|